Prompt Engineering Patterns That Actually Work in Production
The gap between a working demo and a reliable production system is engineering discipline around inputs, outputs, and failure handling.

The gap between a working demo and a reliable production system is engineering discipline around inputs, outputs, and failure handling.
The future of AI lies in compact, efficient small language models that deliver powerful capabilities directly on edge devices.
A 128K context window does not mean you should use 128K tokens. The evidence shows that more context often means worse answers, higher costs, and slower responses.

Choosing an LLM provider is not a model quality decision. It is a vendor risk, data governance, and total cost of ownership decision.

Fine-tuning and RAG solve different problems. Choosing wrong wastes months of engineering effort. Here is how to decide.
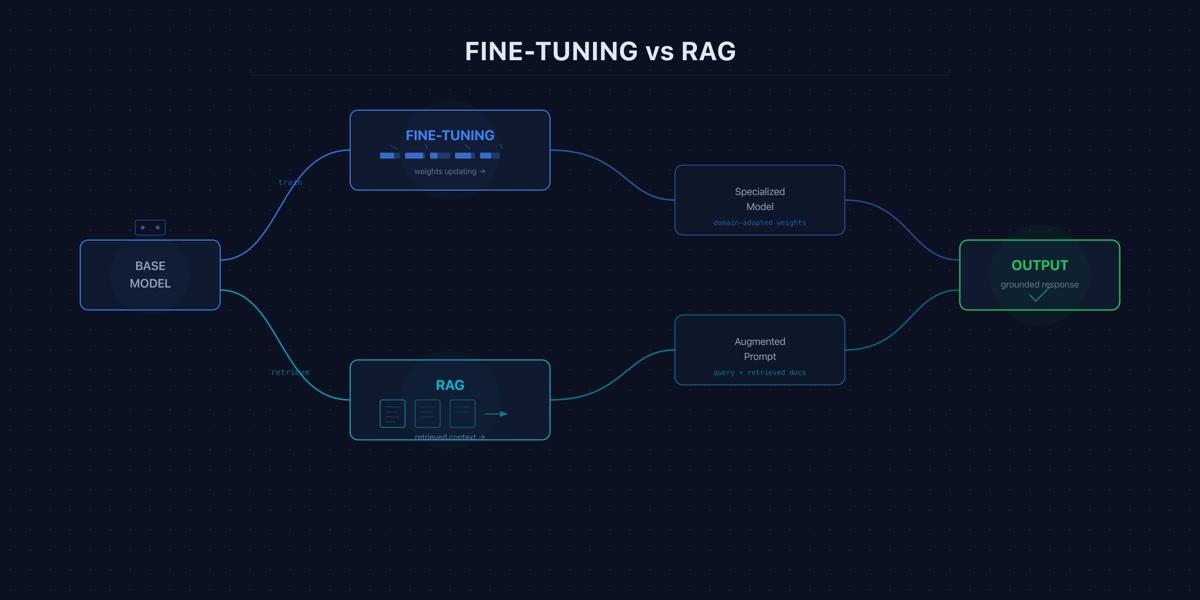
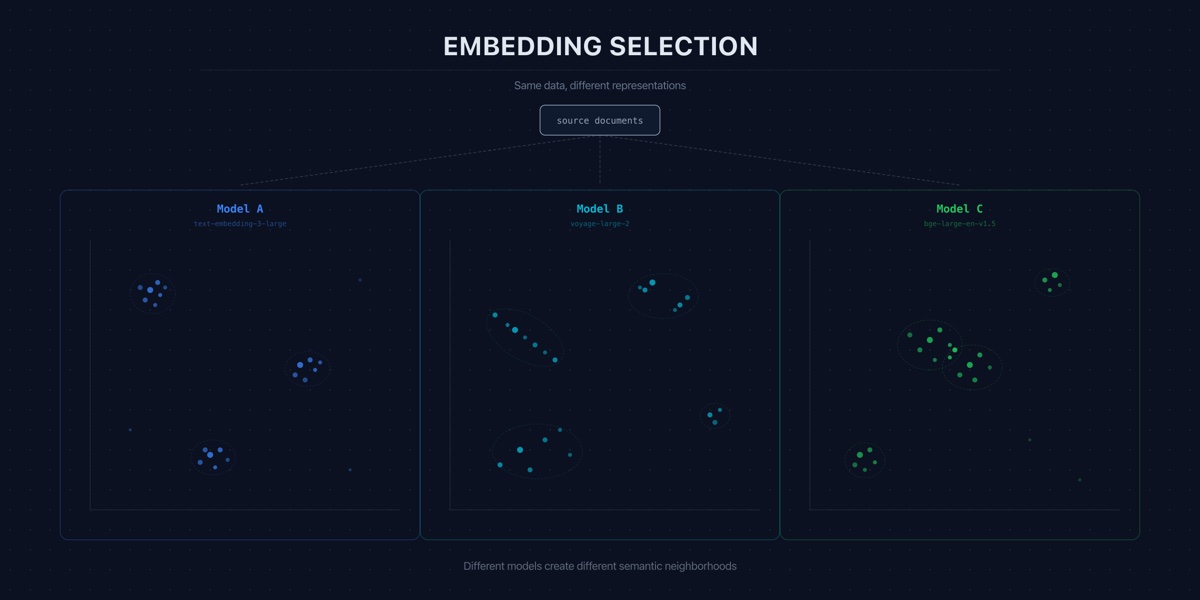
The embedding model is the foundation of your RAG system. Choose wrong and no amount of prompt engineering or re-ranking will compensate.
As production volume scales, the shift from managed APIs to hosted open-weight models isn't just about cost — it's about latency, privacy, and long-term IP ownership.

Vibe checks do not scale. This playbook covers deterministic evaluators, model-graded rubrics, and assertion-based testing patterns that bring LLM outputs under CI discipline.
Deploying a RAG system is straightforward. Knowing whether it actually works is harder.
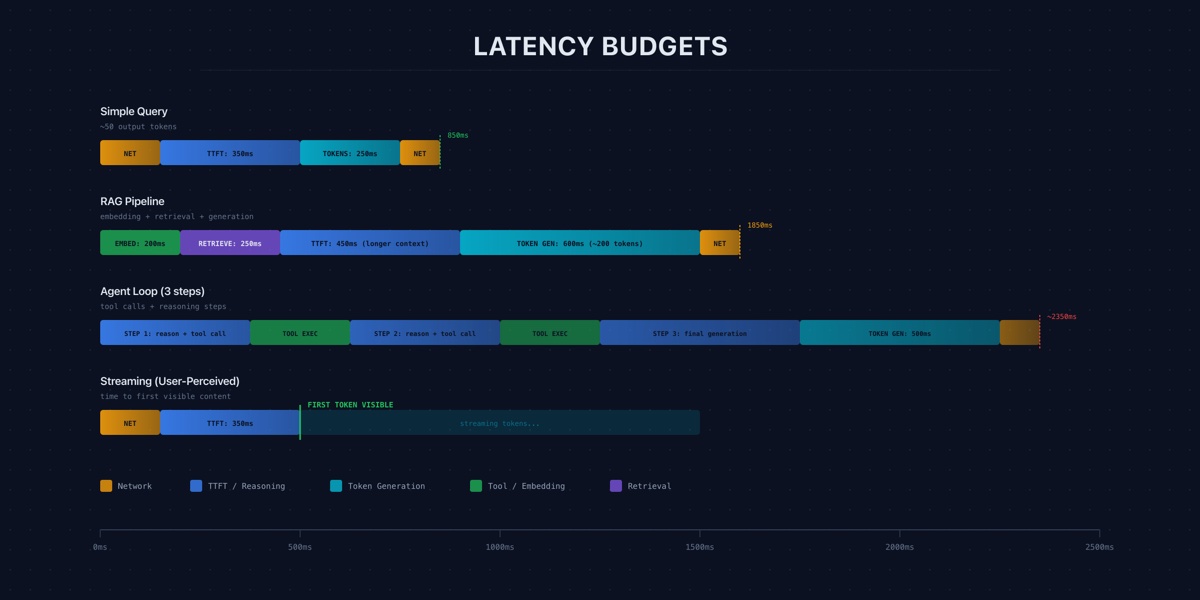
Users do not experience benchmark throughput. They experience time-to-first-token, streaming speed, and total wait time. Here is how production teams measure and budget for each.
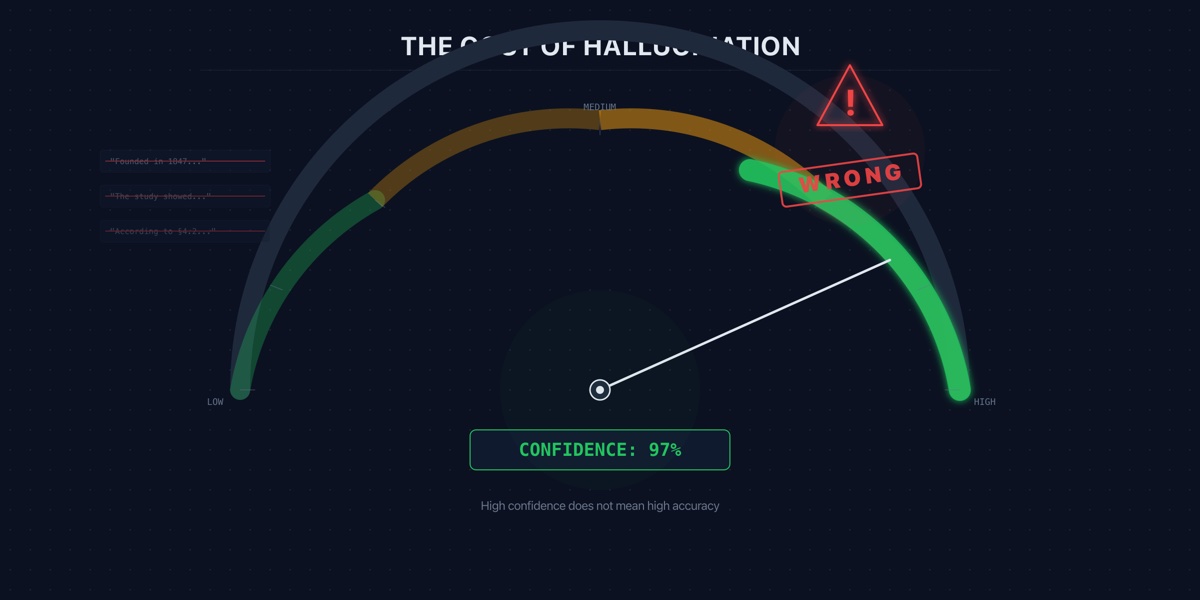
Hallucination is not a research curiosity. It is an operational cost with legal, reputational, and engineering consequences that compound at scale.
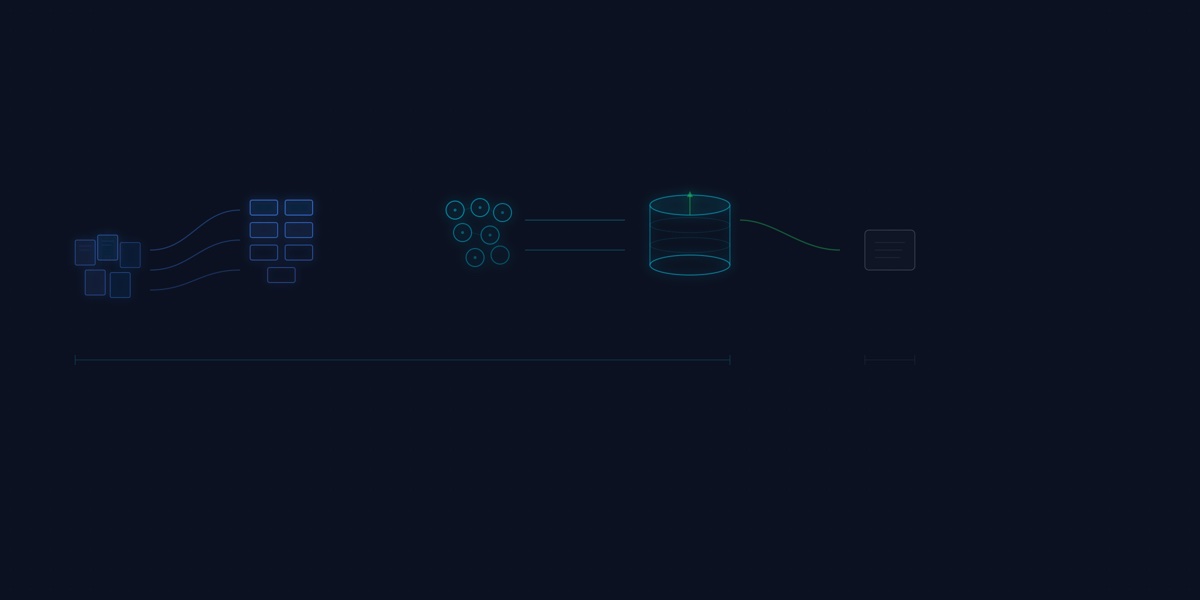
The most performant LLM systems are moving logic out of the prompt and into the data layer. Prompt engineering gets the attention. Data engineering gets the results.
A lean, locally deployable RAG framework that allows a compact 1.5B model to rival much larger models on domain tasks.