Context Window Management: Why Bigger Is Not Always Better
A 128K context window does not mean you should use 128K tokens. The evidence shows that more context often means worse answers, higher costs, and slower responses.

A 128K context window does not mean you should use 128K tokens. The evidence shows that more context often means worse answers, higher costs, and slower responses.
Choosing an LLM provider is not a model quality decision. It is a vendor risk, data governance, and total cost of ownership decision.

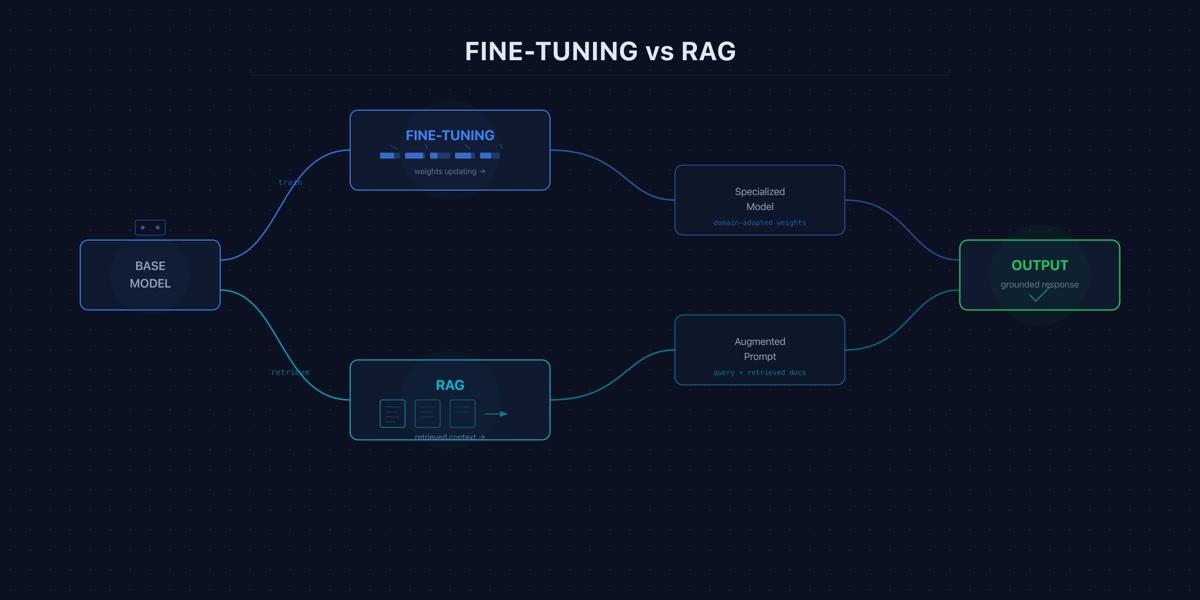
Fine-tuning and RAG solve different problems. Choosing wrong wastes months of engineering effort. Here is how to decide.
As production volume scales, the shift from managed APIs to hosted open-weight models isn't just about cost — it's about latency, privacy, and long-term IP ownership.

The future of AI lies in compact, efficient small language models that deliver powerful capabilities directly on edge devices.