LLM Latency Budgets: What Production Teams Actually Measure
Users do not experience benchmark throughput. They experience time-to-first-token, streaming speed, and total wait time. Here is how production teams measure and budget for each.
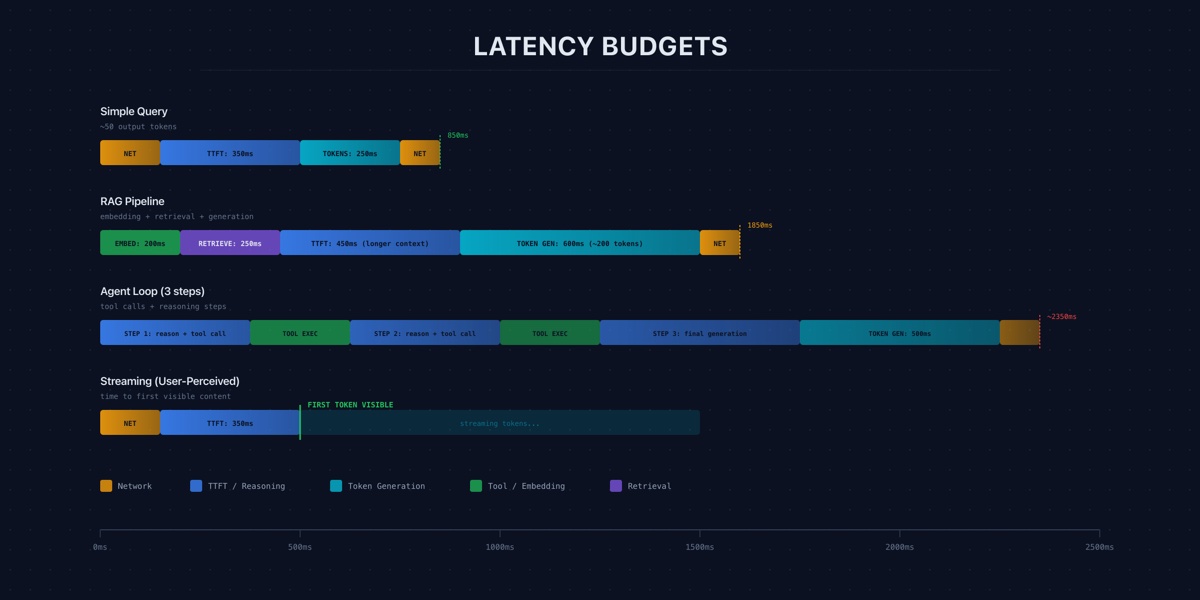
Users do not experience benchmark throughput. They experience time-to-first-token, streaming speed, and total wait time. Here is how production teams measure and budget for each.
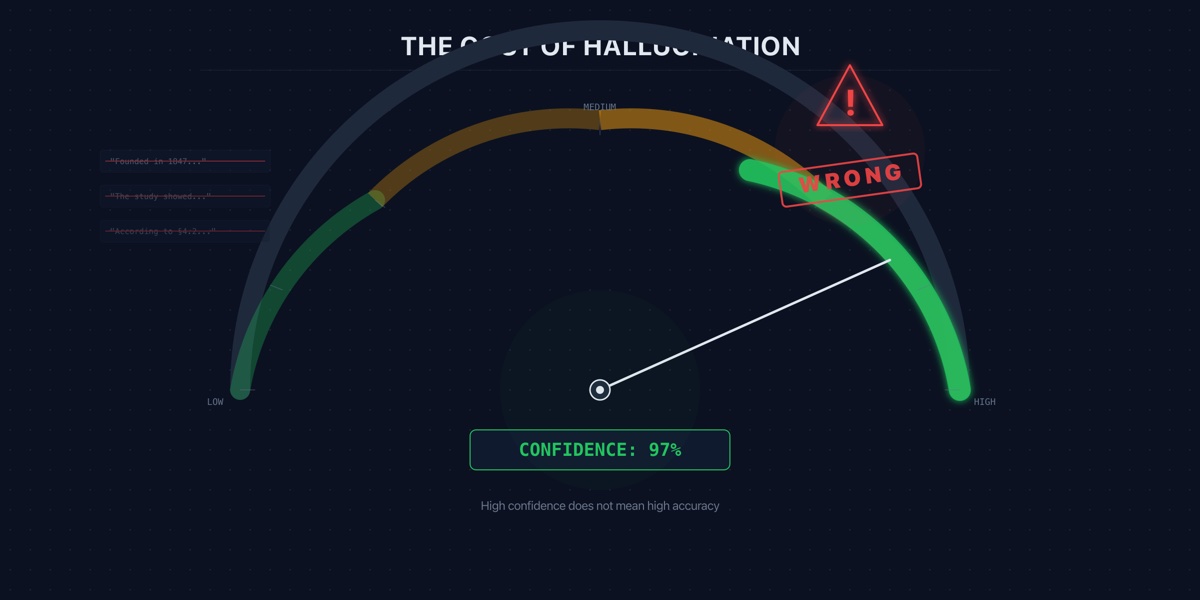
Hallucination is not a research curiosity. It is an operational cost with legal, reputational, and engineering consequences that compound at scale.
The most performant LLM systems are moving logic out of the prompt and into the data layer. Prompt engineering gets the attention. Data engineering gets the results.
A lean, locally deployable RAG framework that allows a compact 1.5B model to rival much larger models on domain tasks.