The Question Is Wrong
Teams building LLM-powered products eventually ask: should we use fine-tuning or RAG? The question implies a choice between two competing strategies. It is the wrong framing, and it leads to the wrong architecture.
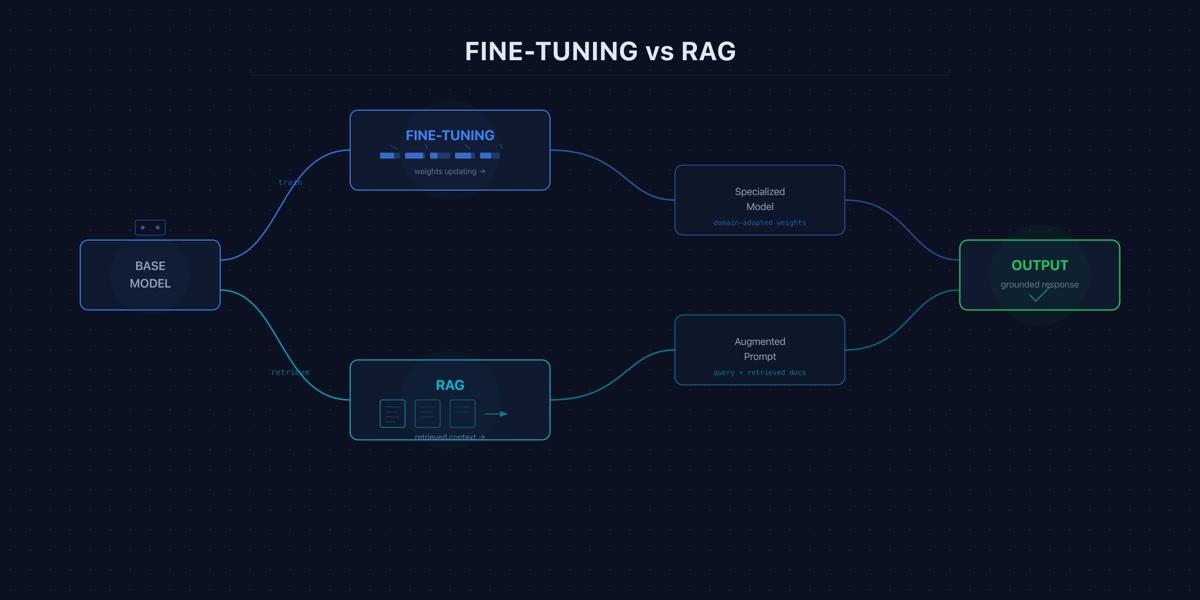
Fine-tuning changes how a model behaves. RAG changes what a model knows at inference time. These are different problems with different solutions, and conflating them is how teams waste months engineering the wrong system for their use case.
A Microsoft Research study across multiple knowledge-intensive tasks found that fine-tuning improved accuracy by 6 percentage points, and adding RAG on top of the fine-tuned model yielded an additional 5 percentage points [S1]. The two techniques were additive, not substitutive. They operated on different axes of model performance entirely.
Yet in practice, most teams treat this as an either/or decision. Enterprise adoption data bears this out: 51% of enterprises have adopted RAG, while only 9% use fine-tuning [S5]. The gap is not explained by fine-tuning being less valuable. It is explained by fine-tuning being less understood, historically more expensive, and perceived as riskier to implement.
Understanding when each strategy wins — and when both are needed — is the difference between a production system that works and one that works well.
When RAG Wins
RAG is the right architecture when the problem is knowledge, not behavior.
If your application needs to answer questions from a corpus that changes — product documentation, legal filings, internal policies, customer records — then the model’s parametric knowledge is the wrong place to store that information. Parametric knowledge is frozen at training time. It cannot be updated without retraining. It cannot be cited. It cannot be audited.
RAG solves all three problems. The model retrieves relevant documents at inference time, grounds its response in those documents, and can point to the specific passages that informed its answer. For any use case requiring attribution or where the underlying data changes more than quarterly, RAG is not optional — it is table stakes [S4].
RAG dominates enterprise adoption for good reason: most enterprise use cases are knowledge problems [S5]. Customer support needs current product information. Internal tools need to query policy documents. Research assistants need to surface relevant papers. The operational profile is favorable — no GPU training runs required, and teams can ship a working RAG system in days.
The limitation is equally clear. RAG cannot change the model’s reasoning patterns, its tone, its output format preferences, or its domain-specific behavior. If you need a model that writes like a radiologist, retrieves evidence like a lawyer, or formats output like your internal reporting standard, RAG alone will not get you there.
When Fine-Tuning Wins
Fine-tuning is the right architecture when the problem is behavior, not knowledge.
Consider a medical documentation system. The model needs to produce notes in a specific clinical format, use domain-appropriate terminology by default, and structure its reasoning in a way that matches clinical workflows. The knowledge — patient records, lab results, imaging reports — can be supplied through RAG. But the behavioral pattern of how the model processes and presents that information is a training problem.
Fine-tuning encodes behavioral patterns directly into the model’s weights. After fine-tuning, the model defaults to the desired behavior without explicit instructions in every prompt — shorter prompts, more consistent outputs, and lower per-call token costs.
The historical barrier was cost. Full fine-tuning of a 40B+ parameter model costs approximately $35,000 per training run [S3]. At that price, experimentation is prohibitive for most teams. A failed training run is not a lesson learned — it is a budget line item.
LoRA changed this calculus fundamentally. Low-Rank Adaptation fine-tunes a small subset of model parameters — typically less than 1% of total weights — while retaining 90-95% of full fine-tuning quality. The cost drops to roughly $300 per run [S3]. At that price, a team can run dozens of experiments in a single sprint. Fine-tuning stops being a high-stakes bet and becomes an iterative process with tight feedback loops.
The use cases where fine-tuning delivers clear returns involve stable behavioral requirements: consistent output formatting, domain-specific language patterns, specialized reasoning chains, or house style adherence. If the desired behavior can be demonstrated through examples and does not change week to week, fine-tuning will encode it more reliably than prompt engineering.
The limitation is symmetrical to RAG’s: fine-tuning does not solve knowledge freshness. A fine-tuned model’s factual knowledge is still frozen at training time.
The Hybrid Approach
The strongest production systems layer both techniques. This is not a theoretical claim. It is an empirical finding.
The RAFT framework — Retrieval Augmented Fine-Tuning — trains models to reason effectively with retrieved documents while learning to ignore irrelevant distractors in the retrieval results [S2]. On PubMed QA, RAFT achieved 73.3% accuracy compared to 58.8% for RAG alone — a 14.5 percentage point improvement [S2]. The fine-tuning did not replace retrieval. It made the model better at using retrieved information.
This pattern generalizes. Fine-tuning teaches the model how to reason within a domain. RAG supplies the current facts to reason over. The Microsoft Research findings confirm the same dynamic: fine-tuning and RAG contributed independently to accuracy improvements, with the combined approach outperforming either alone [S1]. Each technique addressed a different source of error.
For production teams, the hybrid approach means maintaining two systems: a retrieval pipeline and a fine-tuning pipeline. The operational complexity is real. But for high-value domains where both behavioral consistency and knowledge freshness matter — clinical decision support, legal research, financial analysis — the performance gain justifies the engineering investment.
At $300 per LoRA training run [S3], the cost barrier to trying a hybrid approach is low. The question is not whether your team can afford to experiment with fine-tuning on top of RAG. It is whether you can afford not to, given the documented performance gains.
A Decision Framework
Before committing to an architecture, answer three questions:
Does your knowledge base change frequently? If the underlying data updates more than quarterly — product catalogs, regulatory filings, internal documentation — RAG is required. Fine-tuning alone cannot keep pace with dynamic knowledge. This is a necessary condition, not a sufficient architecture.
Do you need consistent behavioral patterns? If your application requires specific output formats, domain-specific reasoning, or stylistic consistency that prompt engineering cannot reliably deliver, fine-tuning addresses the gap. At LoRA-scale costs [S3], the barrier to testing this is low enough that the answer should be empirical, not theoretical.
Are both conditions true? For most high-value production applications, the answer is yes. The knowledge changes and the behavioral requirements are non-trivial. This is the hybrid case, and the evidence suggests it outperforms either technique in isolation [S1, S2].
The 51% RAG adoption and 9% fine-tuning adoption numbers [S5] suggest that most enterprise teams have solved the knowledge problem but have not yet addressed the behavior problem. With LoRA reducing the cost of fine-tuning by roughly two orders of magnitude [S3], the teams that close this gap next will see measurable improvements in output quality — without rebuilding their existing RAG infrastructure.
The right question was never fine-tuning versus RAG. It was: which problem are you solving, and have you addressed both?